RNN(Recurrent Neural Network, 순환 신경망)
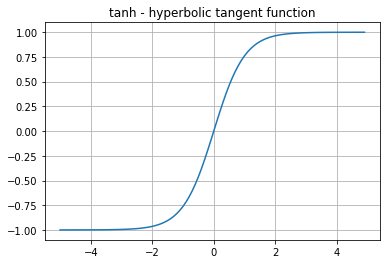
- 순서가 있는 데이터를 처리하기 위한 Neural Network
- 순서가 있는 데이터는 발생 순서가 중요한 데이터
- 은닉층 활성화 함수로 주로 tanh 사용
(값 = -1~1 사이, 기울기 값 = 0~1 사이)
(유사한 sigmoid는 값 = 0~1 사이, 기울기 값 = 0~0.25 사이)
- 데이터의 길이가 길어질수록 앞쪽의 데이터 내용이 뒤쪽으로 전달되지 않아 학습 능력이 크게 감소하는 '장기 의존성' 문제가 존재
ex) 입력한 데이터 x와 참고할 데이터 h 간의 거리가 멀면 그 만큼 까먹을 가능성이 높음
- tf.keras.layers.SimpleRNN(units=, return_sequences=출력 시퀀스의 마지막 출력을 반환할지(False) 아니면 전체 시퀀스를 반환할지(True) 여부설정(보통 RNN층이 하나면 False(기본값), 2개 이상이면 True), input_shape=)
LSTM(Long Short-Term Memory, 장단기 기억 알고리즘)
- RNN의 히든 state에 cell-state를 추가한 구조 (RNN의 장기 의존성 문제 해결을 위해)
- 나중을 위한 정보를 꾸준히 저장(장기 기억)함으로써 오래된 시그널이 점차 소실되는 것을 막아줌
- 즉, RNN에 비해 장기 기억을 하는 연결 성능치가 높음
- 데이터의 길이가 짧으면 RNN, 길면 LSTM
- tf.keras.layers.Embedding(들어가는 숫자의 최댓값(input_dim), 결과값 개수(output_dim), input_length=입력 시퀀스의 길이)
tf.keras.layers.LSTM(units=)
zipfile
- 파일 압축해제 패키지
total_count = 0
with zipfile.ZipFile(args.corpus) as z: # args.corpus 압축해제 후 해당파일 z로 정의
with z.open('kowiki.txt') as f: # z에서 kowiki.txt 파일 열어 f로 정의
for i, line in enumerate(tqdm(f)):
total_count += 1
print(total_count)
#3724301
# enumerate = 해당 데이터를 인덱스 번호와 데이터로 나눠줌
# i = 인덱스 번호, line = 원래 데이터collections
char_counter_tmp = collections.Counter() # 빈도수 출력 dict 형식으로
char_counter_tmp.update(list('아버지가 방에 들어가신다.'))
print(char_counter_tmp)
# Counter({'가': 2, ' ': 2, '아': 1, '버': 1, '지': 1, '방': 1, '에': 1, '들': 1, '어': 1, '신': 1, '다': 1, '.': 1})konlpy(korean natural language processing in python)
- 한국어를 자연어로 분석하고 처리하는 패키지
※ 자연어 = 사람들이 일상에서 사용하는 언어 <-> 인공어 = 프로그래밍 언어와 같이 인공적으로 만들어진 언어
- 4가지 모듈이 존재하며 주로 Okt와 Mecab이 사용됨
from konlpy.tag import Kkma, Komoran, Okt, Mecab
kkm = Kkma(data, flatten=, join=) - 정확도는 높지만 처리 속도가 너무 느림
kom = Komoran(data, flatten=, join=) - 형태소 분석 정확도가 떨어짐
mecab = Mecab(data, flatten=False일 경우 어절 보전, join=) - 정규화 기능
okt = Okt(data, stem=True시 용언이 어간으로 변환되어 출력, join=True시 튜플(형태소,품사)이 아닌 '형태소/품사' 꼴로 출력, norm=True시 정규화 적용) - 빠른 속도
※ 메서드 종류
- pos = 형태소 분리와 함께 해당 형태소의 품사 같이 출력
- morph = 형태소 분리 후 분리된 형태소만 출력 (품사 출력 X)
from konlpy.tag import Kkma, Komoran, Okt, Mecab
mec = Mecab()
okt = Okt()
kkm = Kkma()
kom = Komoran()
txt = '아버지가 방에 들어가신다'
print(mec.pos(txt, flatten=False, join=True)) #mecab
print(kom.pos(txt,flatten=False, join=True)) #komoran
print(kkm.pos(txt,flatten=False, join=True)) #kkma
print(okt.pos(txt,norm=True, stem=True, join=True)) #okt
print(okt.morphs(txt))
# [['아버지/NNG', '가/JKS'], ['방/NNG', '에/JKB'], ['들어가/VV', '신다/EP+EC']]
# [['아버지/NNG', '가/JKS', '방/NNG', '에/JKB', '들어가/VV', '시/EP', 'ㄴ다/EC']]
# [['아버지/NNG', '가/JKS'], ['방/NNG', '에/JKM'], ['들어가/VV', '시/EPH', 'ㄴ다/EFN']]
# ['아버지/Noun', '가/Josa', '방/Noun', '에/Josa', '들어가다/Verb']
# ['아버지', '가', '방', '에', '들어가신다']# 각 형태소에 일련번호 부여하기
morph_to_id = {'[PAD]': 0, '[UNK]': 1}
for w, cnt in morph_counter.items():
morph_to_id[w] = len(morph_to_id)re.sub
- import re
- re.sub(pattern=적용할 패턴 설정(메타문자 이용),reple=최종 출력값 설정, 적용할 데이터)
- 'r'은 문자열에 사용된 이스케이프 시퀀스들을 이스케이프 시퀀스들이 아닌 원시 문자열(raw string)로 만들기 위하여 사용하는 접두사
sentence = re.sub('([,.!?()·])', r' \1 ', sentence) # ,.!?¿()· 중에서 하나가 나오면 양옆으로 띄어쓰기 설정
sentence = re.sub(r'[" "]+', " ", sentence) # " " 빈칸으로 변환
sentence = re.sub(r"[^가-힣0-9a-zA-Z?.!,¿]+", " ", sentence) # 한글,숫자,소문자,대문자,.!,¿ 제외 모두 빈칸으로 변환
# 한글 설정 = 가-힣, 숫자 설정 = 0-9, 소문자 설정 = a-z, 대문자 설정 = A-Z
# URL 제거
text = re.sub('(http|ftp|https)://(?:[-\w.]|(?:%[\da-fA-F]{2}))+', ' ', text)
# e-mail 제거
text = re.sub('([a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+)', ' ', text)
# 숫자 제거
text = re.sub(r'\d+',' ',text)
# 영어 제거
text = re.sub('[a-zA-Z]' , ' ', text)
# 한글 제거
text = re.sub('[가-힣]' , ' ', text)
# HTML 제거
text = re.sub('<[^>]*>', ' ', text)
sentencepiece
import sentencepiece as spm
spm_vocab = spm.SentencePieceProcessor()
text = '아버지가 방에 들어가신다.'
tokens = spm_vocab.encode_as_pieces(text) # 형태소 별로 토큰화 (encode_as_pieces)
# ['▁아버지가', '▁방', '에', '▁들어가', '신', '다', '.']
spm_vocab.decode_pieces(tokens) # 토큰을 문자열로 복원 (decode_pieces)
# '아버지가 방에 들어가신다.'
_ids = spm_vocab.encode_as_ids(text) # 형태소 별로 토큰화한 후 일련번호 설정 (encode_as_ids)
# [5608, 648, 14, 2188, 197, 48, 7]
spm_vocab.decode_ids(_ids) # 숫자를 문자열로 복원 (decode_ids)
# '아버지가 방에 들어가신다.'
spm_vocab.piece_to_id(tokens) # token을 숫자로 변경 (piece_to_id)
# [5608, 648, 14, 2188, 197, 48, 7]
spm_vocab.id_to_piece(_ids) # 숫자를 token으로 변경 (id_to_piece)
# ['▁아버지가', '▁방', '에', '▁들어가', '신', '다', '.']
'빅데이터 부트캠프 > 머신러닝&딥러닝' 카테고리의 다른 글
| 빅데이터 부트캠프 26&27일차 (1) | 2022.08.10 |
|---|---|
| 빅데이터 부트캠프 25일차 (0) | 2022.08.08 |
| 빅데이터 부트캠프 23&24일차 (0) | 2022.08.05 |
| 빅데이터 부트캠프 22일차 (0) | 2022.08.04 |
| 빅데이터 부트캠프 21일차 (0) | 2022.08.03 |


댓글