pandas
- numpy를 내부적으로 활용
- 많은 양의 데이터를 로드해서 분석하는데 최적화
- 데이터분석에 특화된 데이터 구조를 제공
- 다른 시스템에 쉽게 연결
- import pandas as pd를 통해 pd로 사용함
- 리스트 데이터를 이용하여 1차원 구조인 Series로 출력
- 딕셔너리 데이터를 이용하여 2차원 구조인 DataFrame으로 출력(Series가 모여 DataFrame 형성)
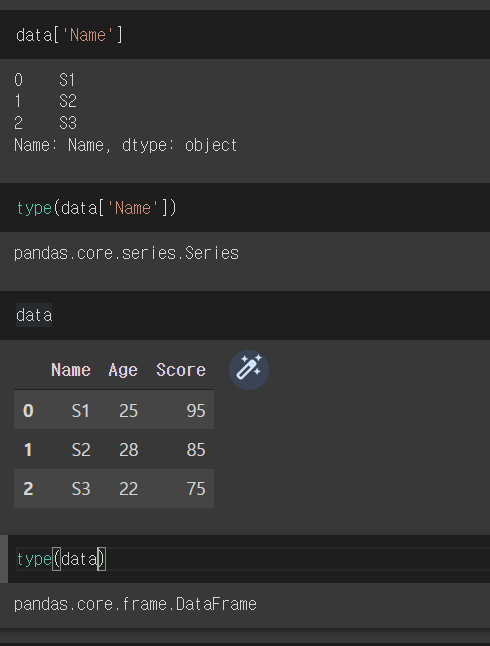
DataFrame
- 엑셀과 같이 인덱스(index), 변수(column), 값(value)로 이루어진 pandas의 특수한 자료형.
- 열백터가 기본 백터
- DataFrame에서 .copy()는 기본적으로 deepcopy
- 인덱싱을 이용하여 데이터 수정 가능
ex) data['Name'][0] = '신짱구'
- 인덱스 번호를 0이 아닌 1부터 사용하고 싶으면 df.index += 1
- 조건 설정 후 원하는 데이터 출력 가능 (불린 인덱싱)
ex) df[df['Score']=>80] = 점수 80점 이상 데이터 출력
- 데이터 변경시 ()안에 inplace=True를 입력해줘야 원본에 반영
- 딕셔너리 데이터에서 필요한 키값만 선택한뒤 columns에 적용함을 통해 원하는 데이터로만 DataFrame 출력 가능
ex) data = {'Age': [25, 28, 22], 'Name': ['S1', 'S2', 'S3'], 'Score': [95, 85, 75]}
df1 = pd.DataFrame(data, columns=['Name', 'Score'])

- DataFrame 출력시 columns에 해당 딕셔너리에 없는 새로운 키 값을 추가할 수 있음 (다만, value값들은 모두 NaN)
ex) df1 = pd.DataFrame(data, columns=['Name', 'Score', 'Tel'])
- A['Name'] = B['Name'] 와 같이 다른 DataFrame에 있는 key-value 값을 가져와 추가할 수 있음
- DataFrame 특정 행 라벨 삭제 : drop([ ], axis= 0)
- DataFrame 특정 열 라벨 삭제 : drop([ ], axis= 1)
iloc와 loc
- loc = 문자열 데이터를 이용하여 원하는 row에서 원하는 column 선택하는 DataFrame 출력 방식
ex) df.loc['1번'] = index '1번'에 해당하는 전체 데이터 출력
df.loc['1번', '국어'] = index '1번'의 '국어'에 해당하는 전체 데이터 출력
- iloc = 인덱스 번호를 이용하여 원하는 row에서 원하는 column 선택하는 DataFrame 출력 방식
ex) df.iloc[1, 2] = 1행 2열의 데이터, df.iloc[[0, 1], 2] = 0행과 1행의 2열 데이터
df.iloc[[0, 1], [2, 3]] = 0행과 1행의 2,3열 데이터, df.iloc[0:2, 2:5] = 0~1행의 2~4열 데이터
- loc, iloc 모두 슬라이싱으로 조건 적용후 출력 가능
- loc로는 df.loc[조건, 입력할 데이터의 column]으로 데이터 추가 가능
ex) df.loc[df['Score']>=80, 'Result'] = 'Pass'
'빅데이터 부트캠프 > Python' 카테고리의 다른 글
| 빅데이터 부트캠프 12일차 (0) | 2022.07.19 |
|---|---|
| 빅데이터 부트캠프 11일차 (0) | 2022.07.18 |
| 빅데이터 부트캠프 10일차 (0) | 2022.07.15 |
| 빅데이터 부트캠프 9일차 (0) | 2022.07.14 |
| 빅데이터 부트캠프 8일차 (0) | 2022.07.13 |


댓글